

想必大家对黑科技已经饥渴难耐了~
今天给大家带来@shingyu大神编写的两款小说下载工具,目标平台为Fan茄和Qi猫使用该工具可将作品以txt格式保存至本地,编译成品和源码都在项目主页可以下载,可供学习和研究使用!
1、小说下载Tool

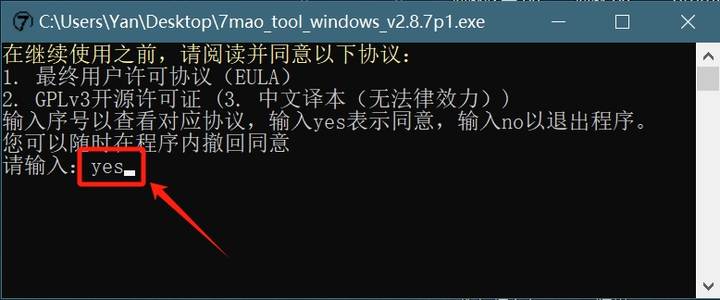
使用平台:Win、macos、ubuntu软件采用 Python 编写,使用前需阅读相关协议,同意则需输入yes敲击回车开始使用。
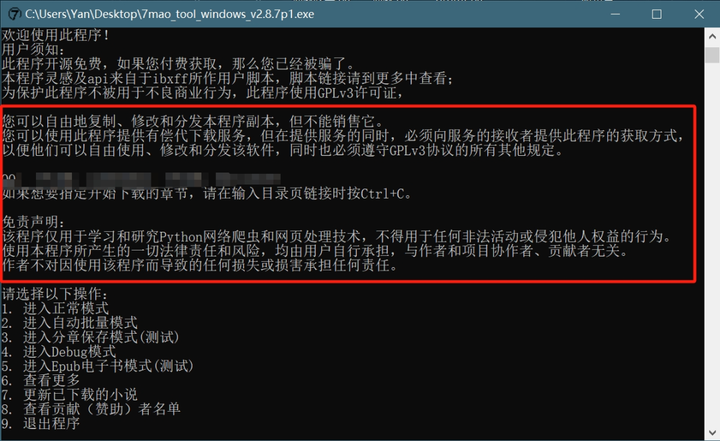
看到这种命令行界面不要怕,各类提示和选项作者已经安排的明明白白了,可以直接傻瓜式使用。接下来我们只需输入“1”,回车进入正常模式,然后前往对应官网复制任意小说链接地址,粘贴至软件后再次敲击回车。文件将以txt格式保存至本地指定位置。
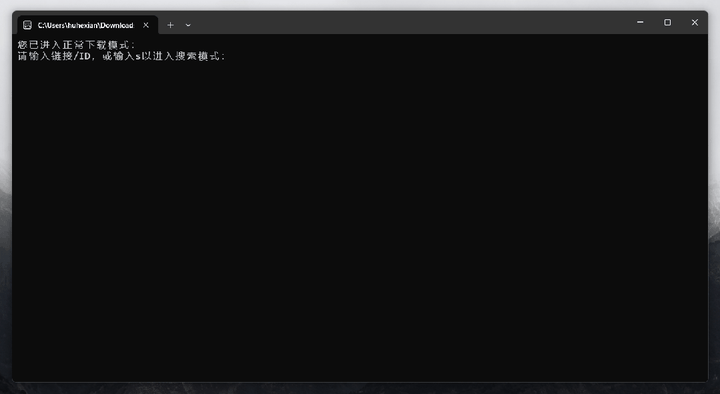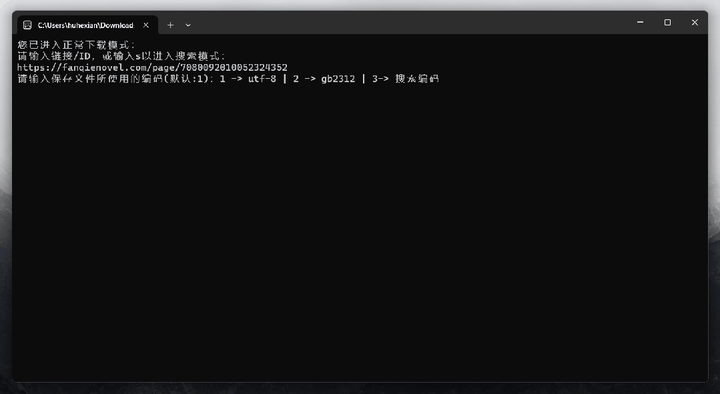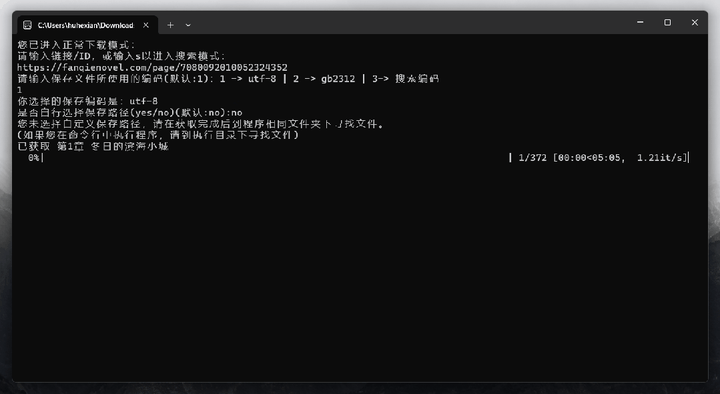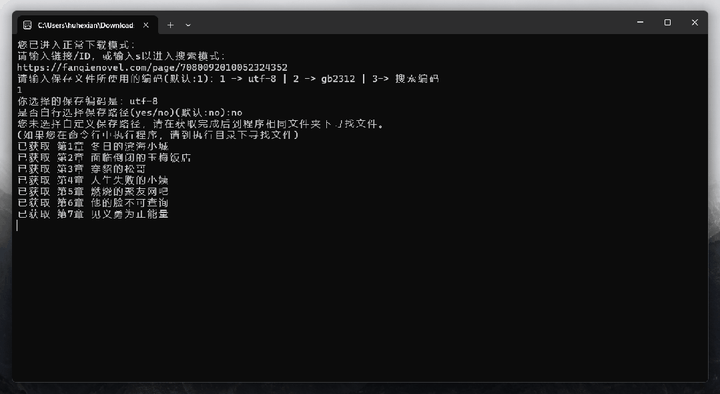
该工具的特点比较多,如允许用户在保存文件时选择UTF-8和GB2312编码之间的编码格式。亦或者支持保存txt、epub两种格式……感兴趣的小伙伴可以自行测试~
2、小说规则下载器
下载小说的整体思路和两年前一样,我们需要一个小说目录页的链接,并为它创建一个任务。目录页的链接没啥好说的,任意一个小说站的任意一本小说都有。
软件特色
自定义规则下载,能对大部分小说网进行文章下载,个别网站对书籍分类详细的,还支持多书籍下载;
自带大量预计网站,不会定义规则的用户可以直接套用,一样能下载到需要的小说;
提供常用规则选择,适用于大部分网站,方便快速定义规则;
支持多线程下载,能实现高速下载书籍,甚至能根据下载情况自动切换下载模式;
自带源代码查看器,提供链接分析、关键定位、标签分段等工具;
下载前能对目标章节进行排序、删除、甚至是过滤重复等操作,让下载的书籍阅读起来更加顺畅;
下载前提供章节自动查重、排序、转换章节号、重置连续章节号等功能;
自动分析查找非正文章节,方便清除与小说无关内容以及规范章节号的编排;
针对大型小说,将任务暂存于数据库后可随意中断、恢复任务;
书籍提供多种输出方式:按章节文件、独立文本文件、压缩包、ePub电子书籍等;
支持章节分页的下载,分页数量可以调整,支持动态分页情况(即分页数量不固定);
支持任务导入,即从存有章节页面链接的文本文件、excel 文档中导入任务进行下载;
所有组件支持提示信息,即光标停置后会显示相关提示,大部分操作支持状态栏提示,让使用变得加容易;
支持预设网站的添加、修改、导入、导出、排序、删除;
提供书籍下载记录,可查看历史下载信息,方便重新下载。
更新日志
【新增功能】
添加对链接访问时请求数据包的设定(即请求头),可以设置软件默认的数据包,还可以针对预设网站、下载任务设定不同的请求数据包,它们相互之间可以方便复制引用,甚至可以利用浏览器的开发者工具复制多组数据块,软件可以自动识别数据并添加。
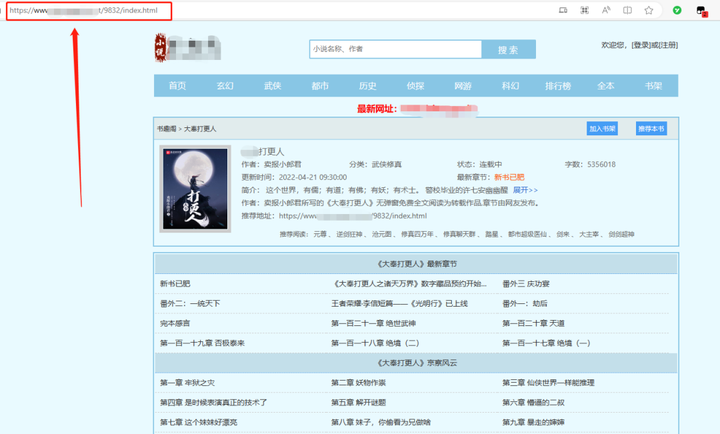
至于在下载器里的具体步骤,点击左上角的「创建自动任务」按钮,在新的弹窗页输入链接,最后点击「捕获目录」。
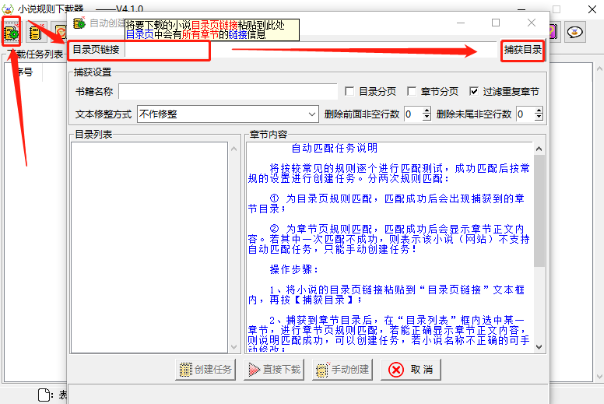
坐等下载器解析完目录页,它会把所有章节全都提取出来。
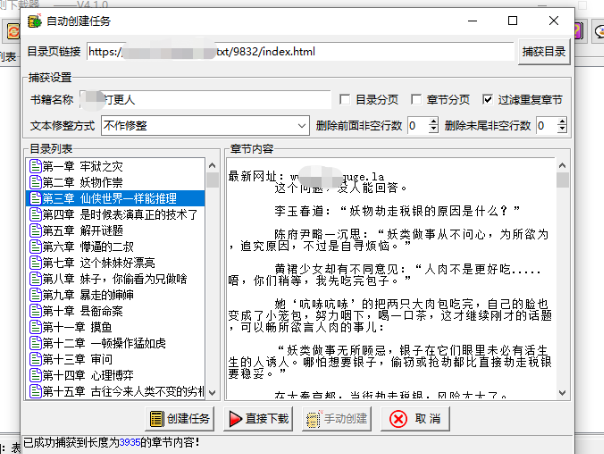
细节上,但凡能选的地方,鼠标悬停皆有介绍,如果小说站的目录页是分页形式,记得勾选对应的选项。
不过更值得一提的是下面一行「删除非空行数」的功能,它是做什么的你肯定不陌生,在提取出来的目录里,任选一章点进去,开头结尾处多半是有站点的推广信息。
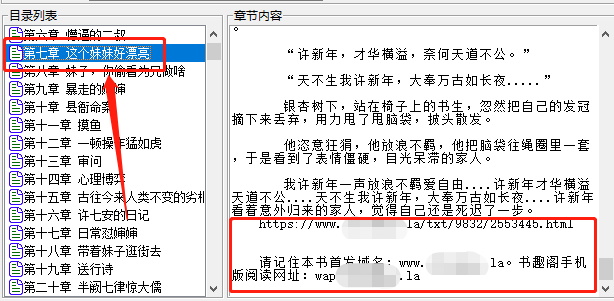
小说站点是批量往上加的,咱们的下载器可以批量删除,数数有几行推广信息,末尾删除行数就改成几。
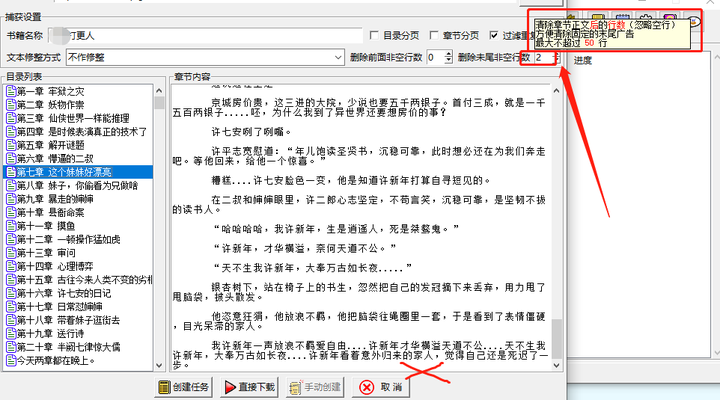
注意,这里批量删除的行数是不包含空行的,以及如果使用这个功能,建议放大窗口看,原因无他,在小窗口下会自动换行,容易影响判断。。。
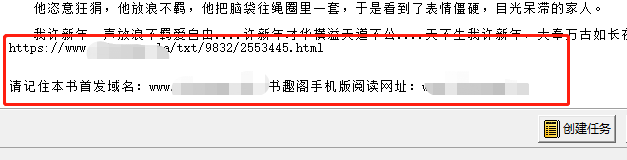
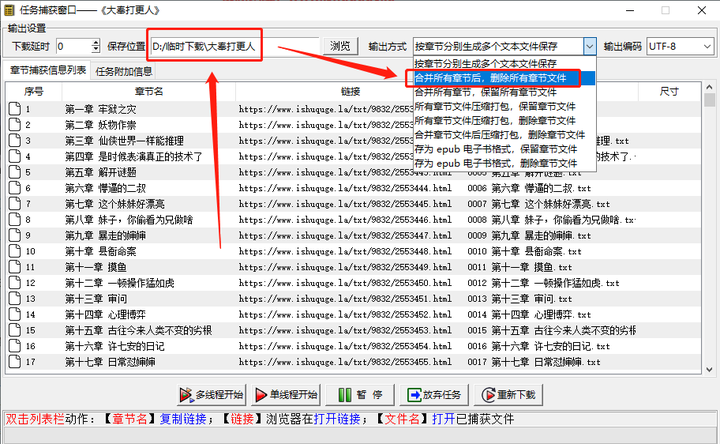
处理好了这些,点击「直接下载」,会跳转到「任务捕获窗口」页,需要更改的有两项,一个是「保存位置」,一个是「输出方式」。前者就是保存目录,没啥说的,需要自己 Copy 文件夹地址进去;后者默认是每一章一个 txt 文件,如果没有特殊需求的话,还是「合并后删除」更适合我们。
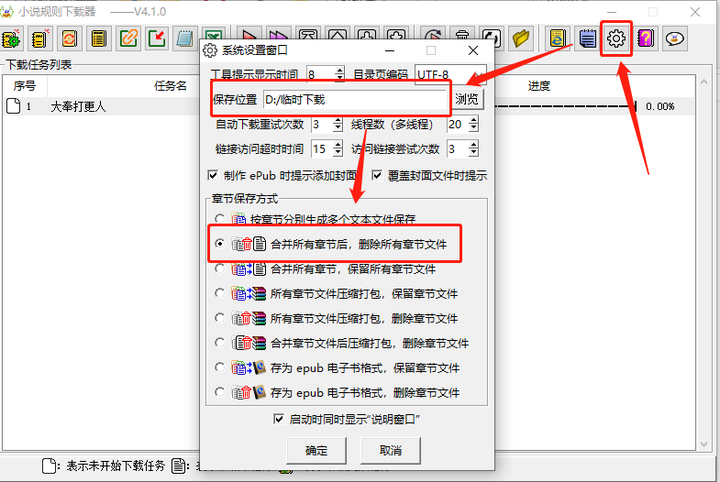
当然,保存位置也好,输出方式也罢,可以在「设置」里提前设定好。
单线程稳,多线程快,这个小说规则下载器,是支持断点续传的,先多线程下载,如果有问题了未下载章节会标红,暂停一下切换到单线程下载即可。
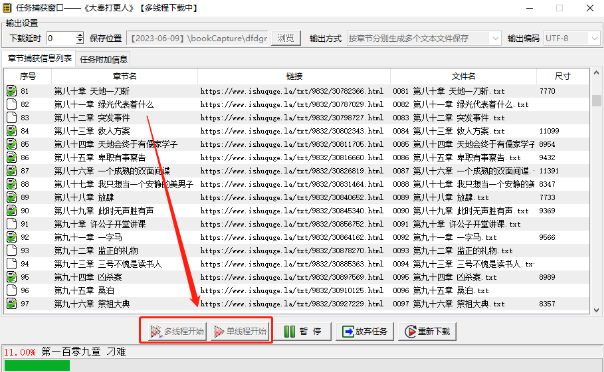
下载完成后,下载记录仍在「下载任务列表」里,如果你是完本的小说,任务删了也就删了。但如果当前小说是连载的,选中任务后,无论是菜单栏里选也好,右键选也罢,下载器会从「目录页」里抓取最新的章节。
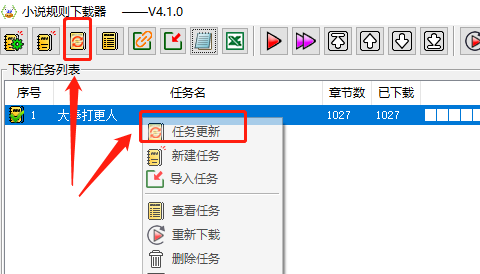
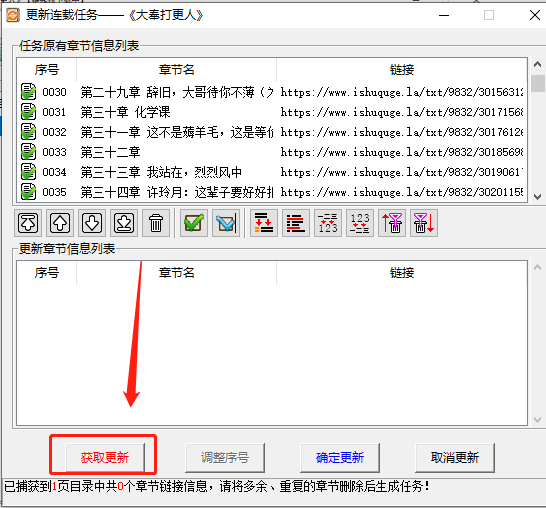
之所以能捕捉下载的这么丝滑,是因为这个下载器里预设有 378 个小说站点的规则。
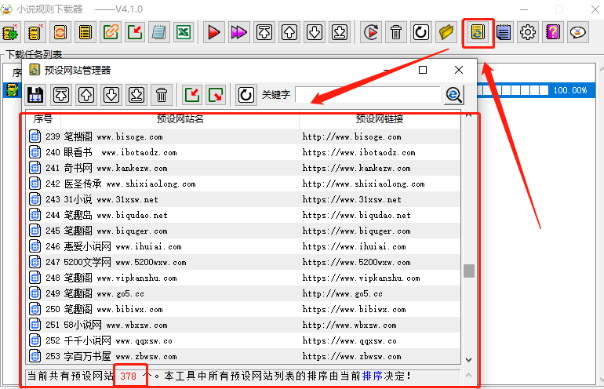
我们创建的自动任务,实际上是从预设模板里匹配到了捕获规则,对于现在源码都差不多的主流小说站点,没错,就是那个笔趣阁宇宙,按作者的话说 100% 能下。

那如果你挑的小说站,恰好不在预设里呢?硬的地方来了,是时候上代码了。进阶玩法今天的这个小说规则下载器本身还支持多种捕获小说规则的方式,不过需要掌握那么点小 tip。比如这个站,我去预设里搜了搜,可惜的是下载器里并没有收录这个域名,更没有规则。
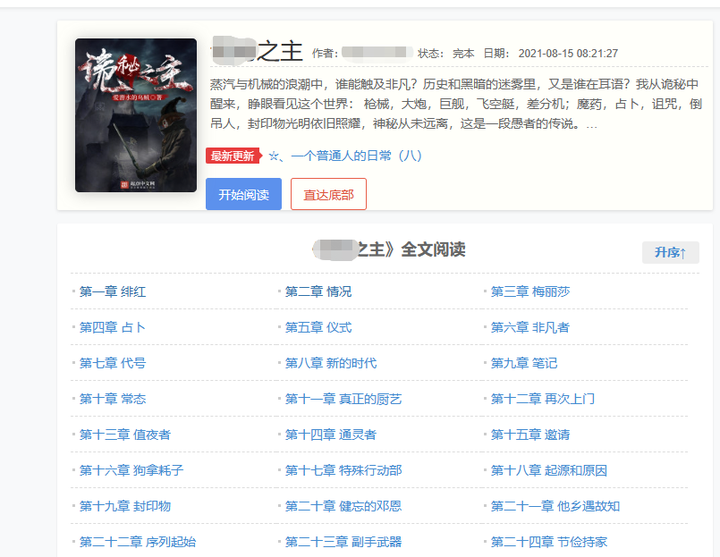
我先对目录页 F12 检查了一下,发现每一章的链接,前面域名没变,变的只有最后的数字,而且是递增的。
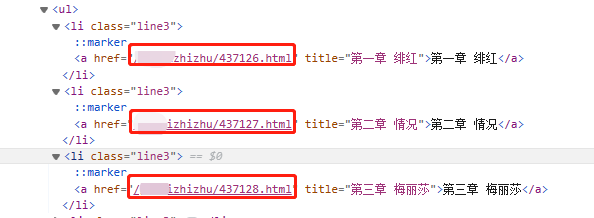
怎么办?小说规则下载器有一个批量添加序列章节链接的功能,把该加的加上去,点击「源代码」瞅一下章节名的标签是什么,再测试一下。
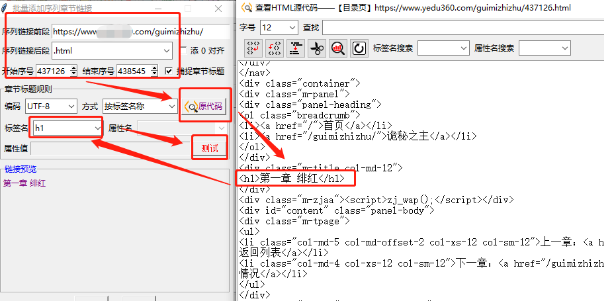
确认后,开始导入,不过还需要我们手动输入书名和保存目录,并设定捕捉章节内容的规则。
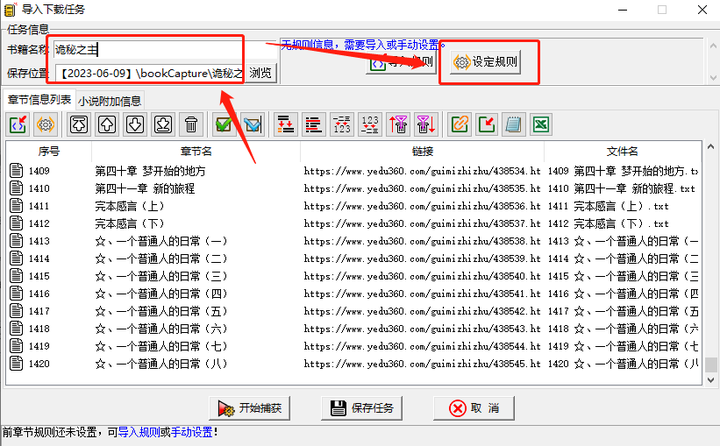
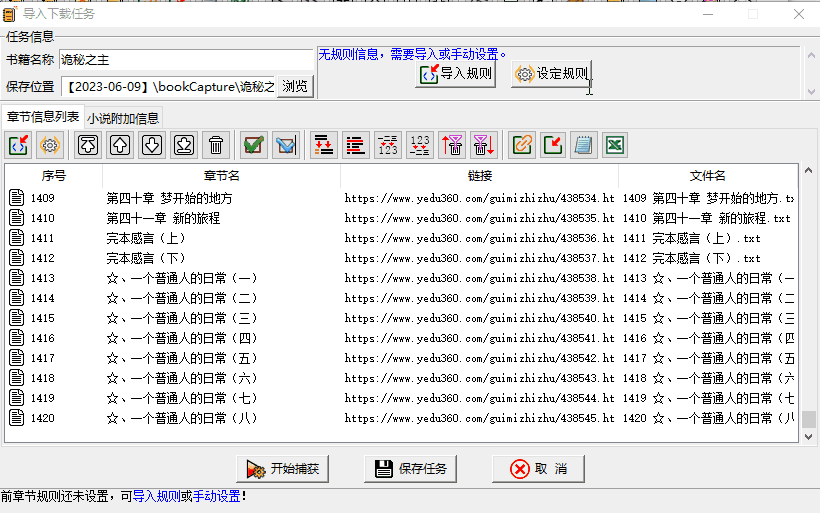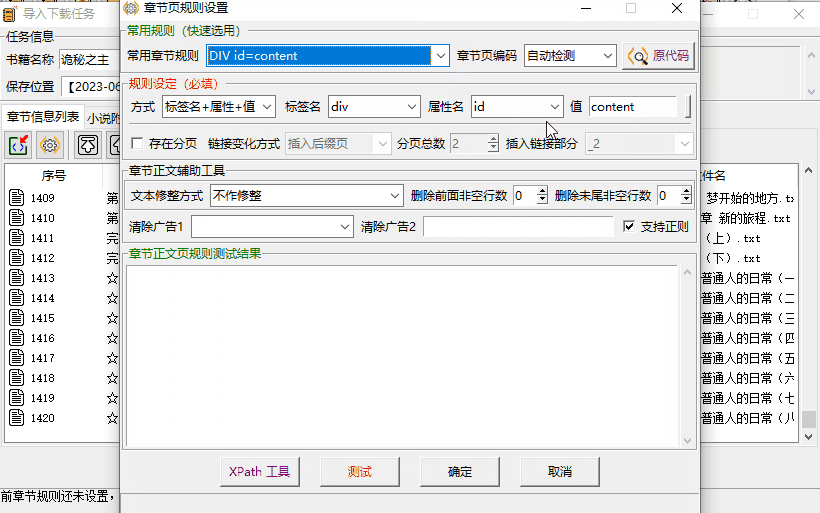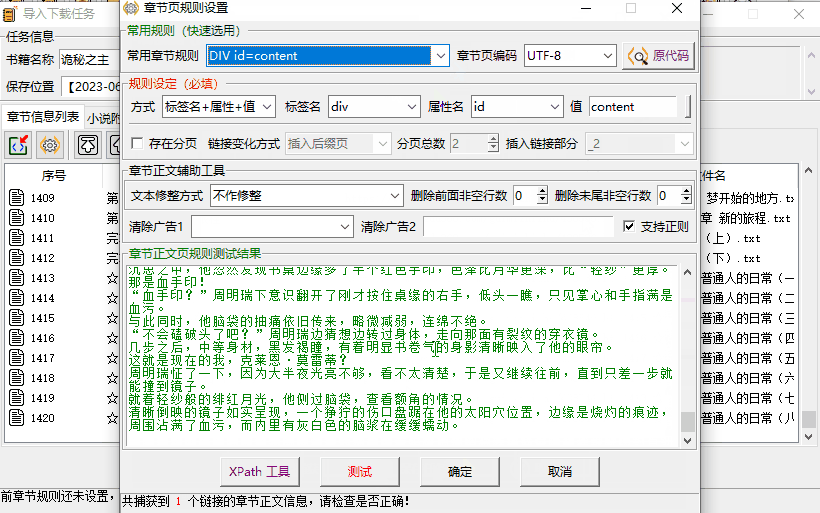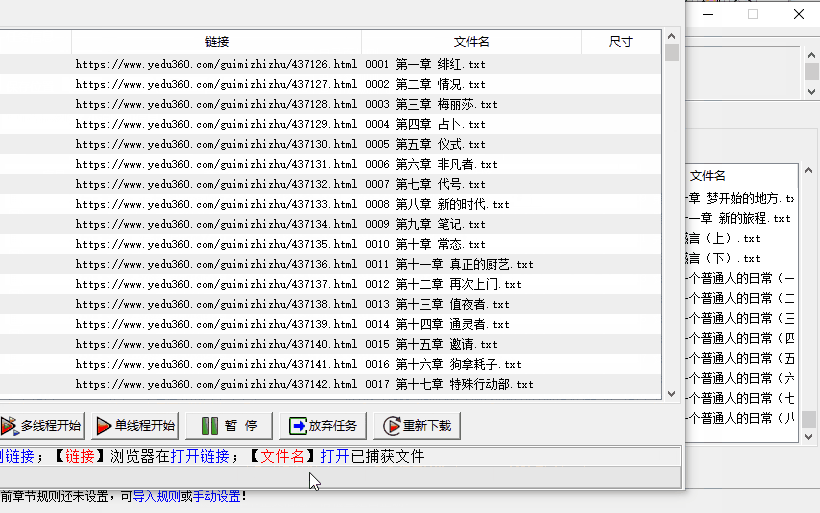
虽说是自己设定,但实际上也有预设的 3 个常用规则,分别选中测试一下,能爬取到完整文字就可以点确定开始下载了。
那万一各章节的链接尾,不是数字递增的怎么办?别急,我们可以自己 DIY 规则。具体操作是手动创建任务,输入链接。
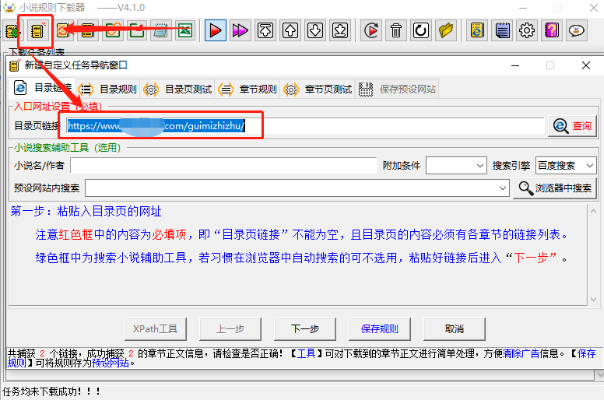
然后你细看后面的步骤,不过是两轮设置规则-进行测试。
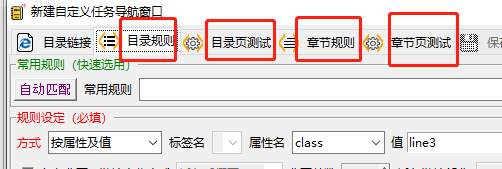
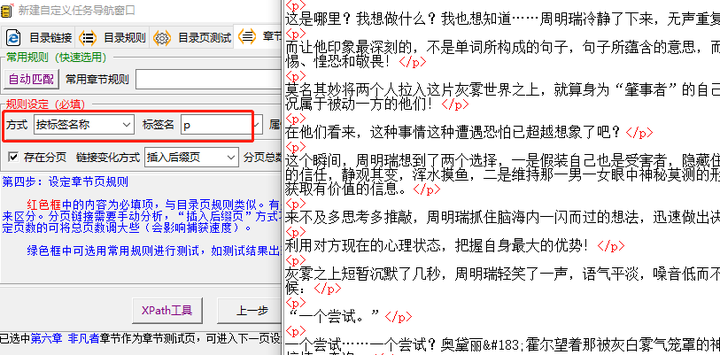
就拿目录来说,你细看一下章节名前后的代码,都有「li」标签,「class」属性,「line3」值。

回到规则设定,只要比葫芦画瓢填写。
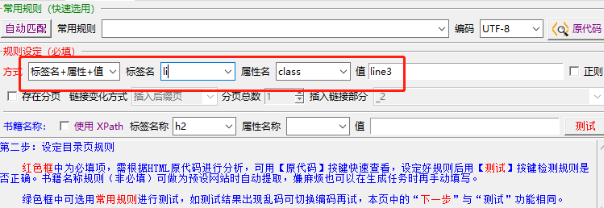
下一步测试后就成功抓到了所有章节。
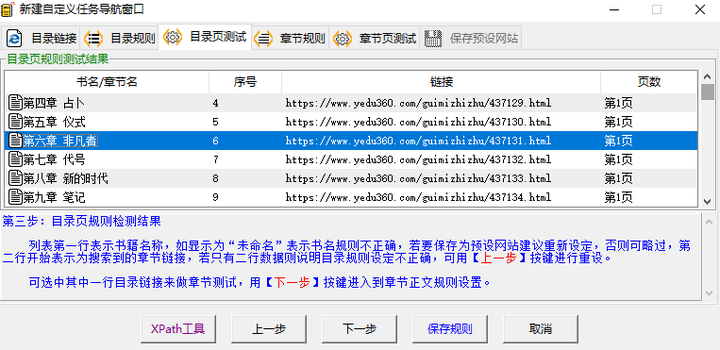
第二轮规则操作一样,看源码发现正文前后都是「P」标签,那直接用「P」标签定位,就能抓到正文。
两轮流程走完,无论你是生成任务开始下载,还是保存规则,下次从这个站点下小说时直接复用,怎样都可以,此时的小说已是你的囊中之物。
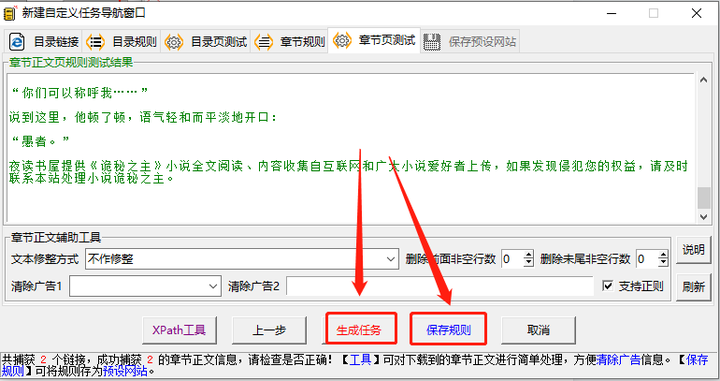
虽然设置规则看着很难,但终归是个熟练工种,下载器内的帮助信息,可以帮你快速掌握。

3、小说规则下载器
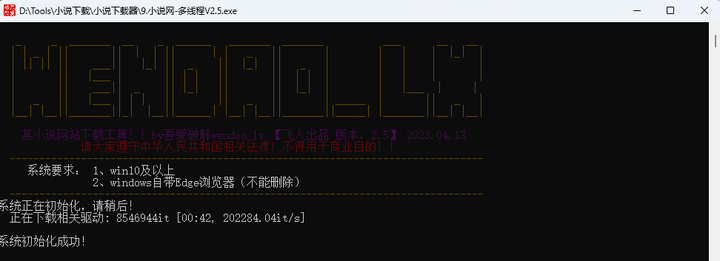
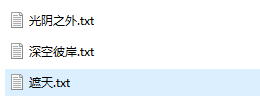
比如:我最近想看的【光阴之外】,输入名称,即可看到最新章节,选择序号即可下载
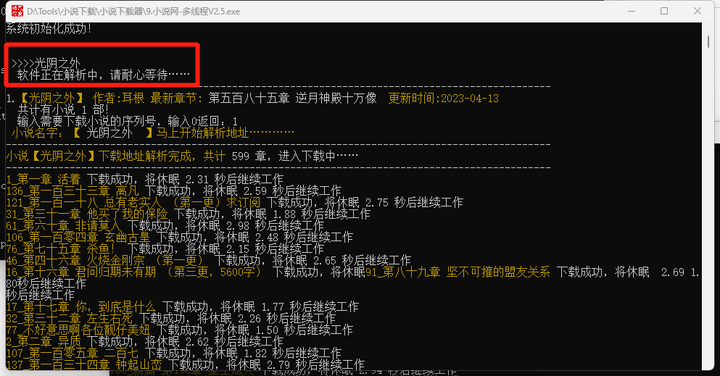
下载完成后,会有章节数,并合并成txt文档,这绝对是离线党的福音。
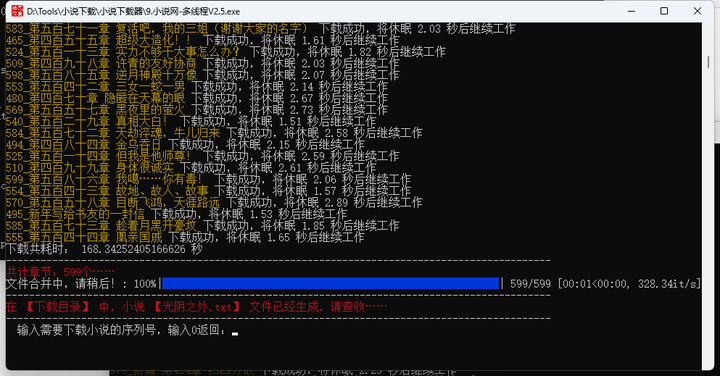
再比如,我要下载【深空彼岸】
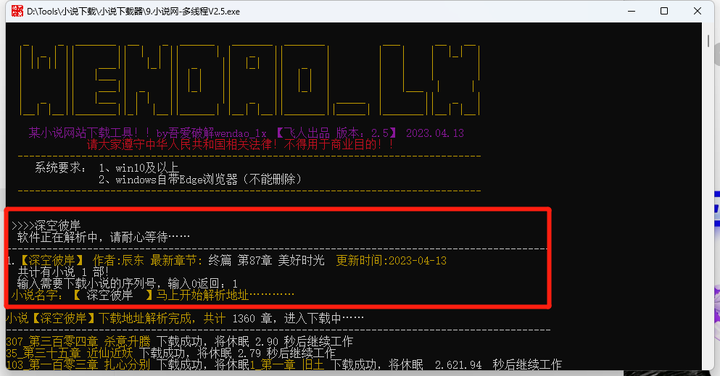
下载完成后,会在程序的主目录会生成一个下载目录文件夹
目录中就是你下载好的小说了
本文转载自:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

评论(0)