

前言
渴望拥有强大且高级的“神器”吗?尽管我们未必精通其背后的复杂原理,但对于技术小白而言,尝试接触并使用某些热门工具并非难事。今天,我要向你推介一款在GitHub上广受追捧,拥有高达28.8K星标的项目——Whisper。借助这款利器,音频转文字的需求无需花费任何费用,只需充分利用你的个人电脑,便可实现离线高效处理!
Whisper
(复制‘Whisper’进入公众号聊天页面回复获取相关资源!)
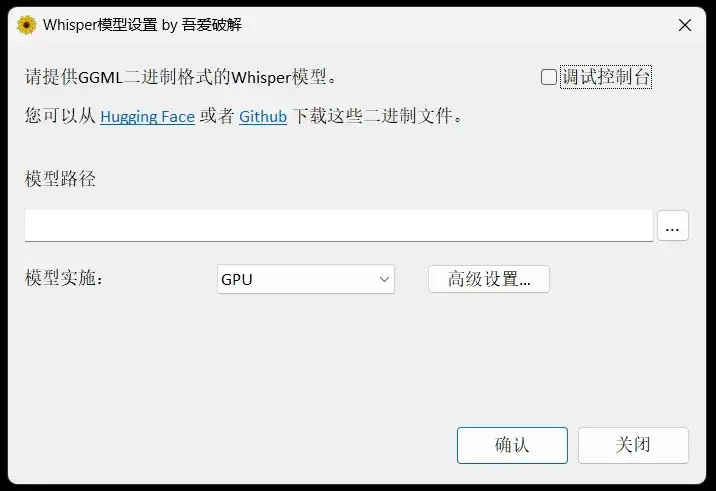
使用平台:Windows适用平台:Windows系统实际上,今天所分享的工具包含了两个关键部分。首先,是一款用于运行大型模型的辅助工具,你可以将其视为空壳,必须与开源的Whisper模型配套使用。
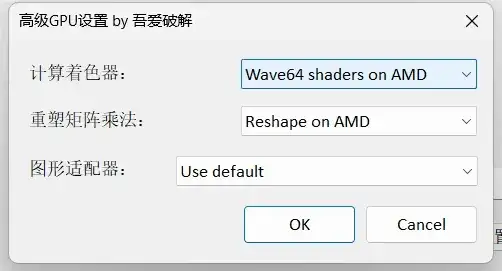
在启动前,请确保在图形适配器设置中选择了独立显卡,以优化性能表现。
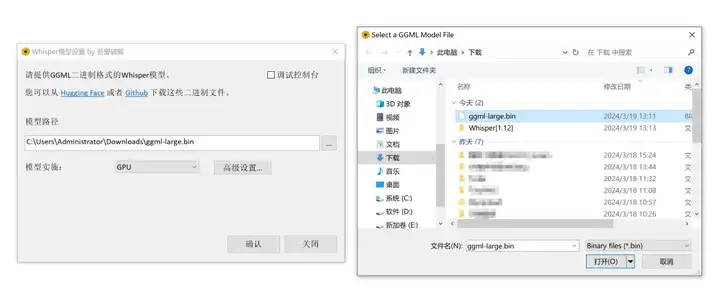
接下来,用户可以从Huggingface或GitHub上下载Whisper的离线大模型进行实际操作。


在成功下载大模型后,我们需要在软件中配置模型文件的实际路径。
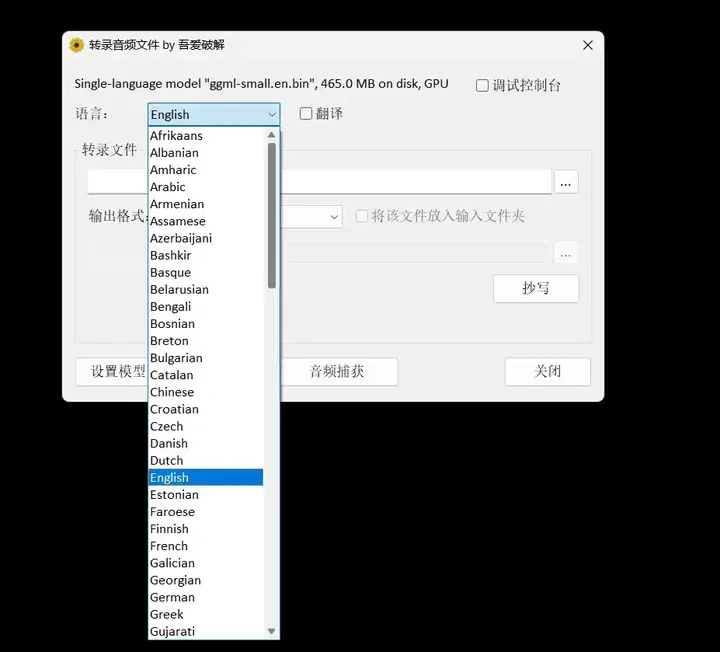
该工具允许用户自定义设置语言选项及是否开启翻译功能,但这些功能的实现依赖于所选用模型的支持。即便你的电脑硬件配置一般,比如搭载GeForce MX250显卡的设备也能基本满足运行要求。
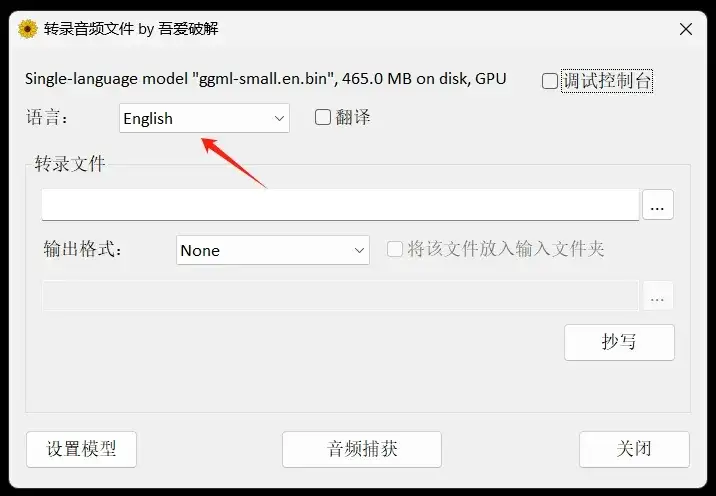
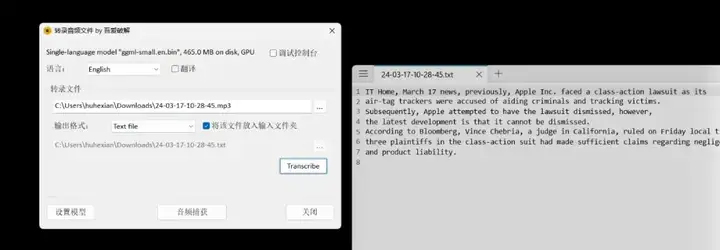
选定待转写的文件(无论是mp3还是mp4格式均可)及输出格式后,单击“转写”按钮,静候转换完成。
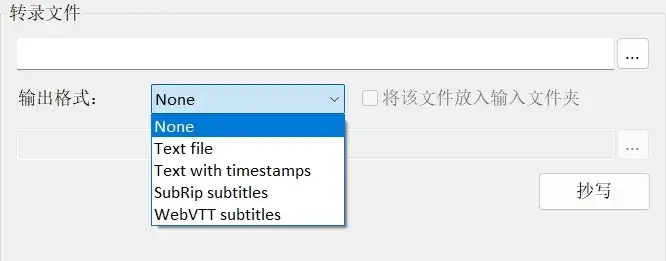
Whisper支持四种不同的输出格式,用户可以根据自身需求自由选择。
转写完成后,软件将展示总耗时、加载速度等相关信息,并在预设的保存位置生成转录后的文本文件。
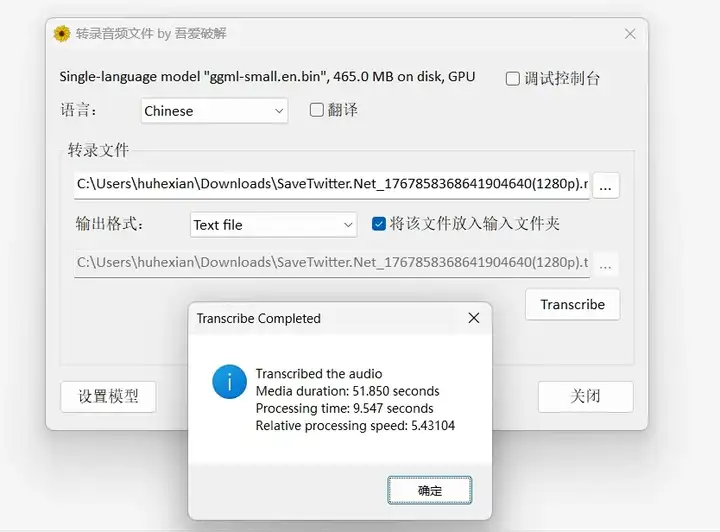
实事求是地说,Whisper在英语语音识别方面展现出了显著优于同类工具的优势,但在中文语音识别方面的表现尚有待提升。
鉴于模型众多且体积庞大,打包提供所有模型并不现实,但不必担忧,我会提供下载地址指引,同时软件内也推荐了官方模型网站,用户可自行挑选下载体验。
资源获取地址:
第一步:文章内部获取资源名称(注意是如下图选中部分的)
第二步:微信扫描图片二维码进入小程序!
第三步:小程序内搜索资源名称!
第四步:找到资源进行下载!
例子:

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

评论(0)